Most email newsletters are garbage
Submitted by Ambrose on Sat, 2020-08-22 14:07
Most newsletters these days aren’t sent with normal mailng list software, but from commercial providers like MailChimp. This probably has a lot to do with the fear of being accused of sending spam.
The thing is most of these newsletters are garbage: long and unpronunciable links, images with no alt text. Since these are often just a series of images, the entire newsletter often contain no information at all – other than the address of the sender at the end.
Here’s a typical link dump, from the Mountain Equipment Co‑op:
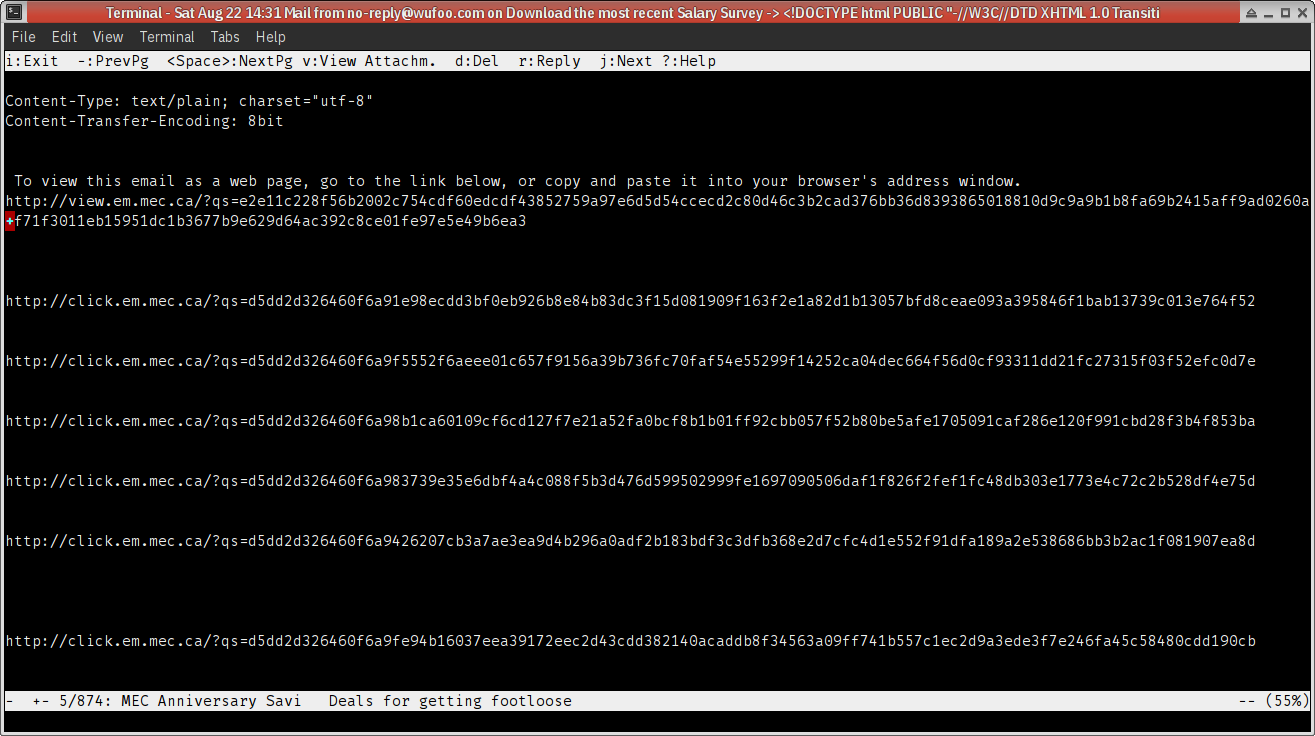
Do you think anyone who sees this kind of garbage will bother opening the images to see what the images say? (Let’s assume you actually can see.) Nope, I don’t think so?
Why then do these companies spend so much time sending garbage like this?
You can do bettter.
And some have done better.
Here’s one from the Association of Registered Graphic Designers:
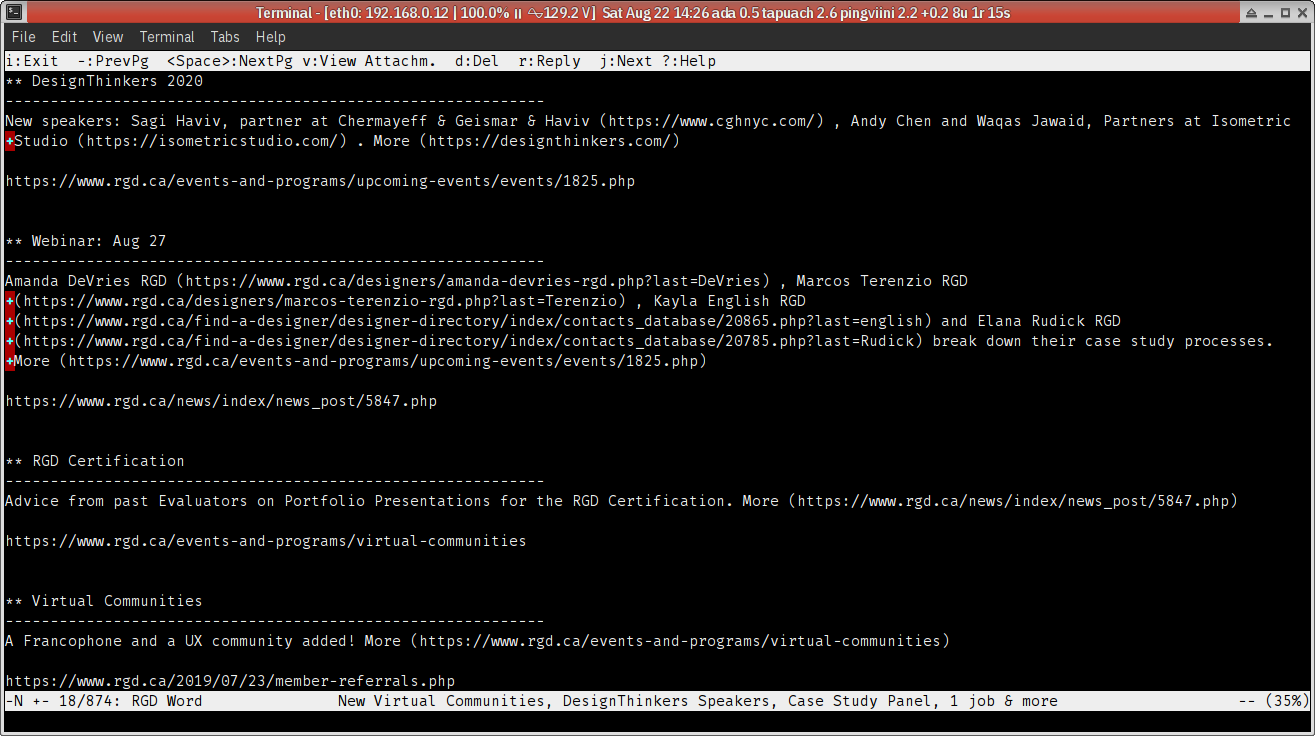
Which one do you prefer, as a reader?